| Initiation Factor | Activity |
| eIF-1 | repositioning of met-tRNA to facilitate mRNA binding |
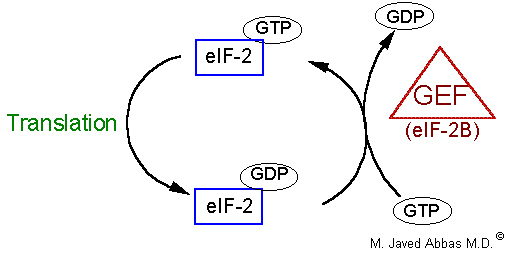
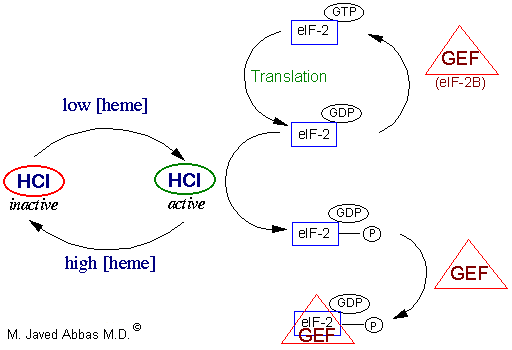
| eIF-2 | ternary complex formation |
| eIF-2A | AUG-dependent met-tRNAmeti binding to 40S ribosome |
eIF-2B
(also called GEF) | GTP/GDP exchange during eIF-2 recycling |
eIF-3
composed of ~10 subunits | ribosome subunit antiassociation, binding to 40S subunit |
eIF-4F
composed of 3 subunits: eIF-4E, eIF-4A, eIF-4G | mRNA binding to 40S subunit, ATPase-dependent RNA helicase activity |
| eIF-4A | ATPase-dependent RNA helicase |
| eIF-4E | 5' cap recognition |
| eIF-4G | acts as a scaffold for the assembly of eIF-4E and -4A in the eIF-4F complex |
| eIF-4B | stimulates helicase, binds simultaneously with eIF-4F |
| eIF-5 | release of eIF-2 and eIF-3, ribosome-dependent GTPase |
| eIF-6 | ribosome subunit antiassociation |